
こんにちは!
皆さんは、ランダムフォレスト(RF)という機械学習アルゴリズムをご存知ですか?
ランダムフォレストは、決定木(Decision Tree)を複数作成してそれらを組み合わせることで、高い精度での予測が可能な機械学習手法の一つです。
特に、分類(Classification)や回帰(Regression)問題において、良い結果を出すことができることで知られています。
今回の記事では、Pythonを用いたランダムフォレストの基礎的な使い方について、以下の内容をご紹介します。
- ランダムフォレストについて
- Python でのランダムフォレストの使い方
ランダムフォレストとは
ランダムフォレストは、複数の決定木を組み合わせたアンサンブル学習法の一つです。
決定木とは
決定木とは、ある入力データに対して、一連の質問を行い、その回答に基づいてクラス分類や回帰を行う機械学習アルゴリズムです。決定木は直感的で解釈がしやすく、説明変数の重要度も可視化することができるため、機械学習において広く使われています。
決定木の詳細については後ほど、記事を公開する予定です。
ランダムフォレストの概要
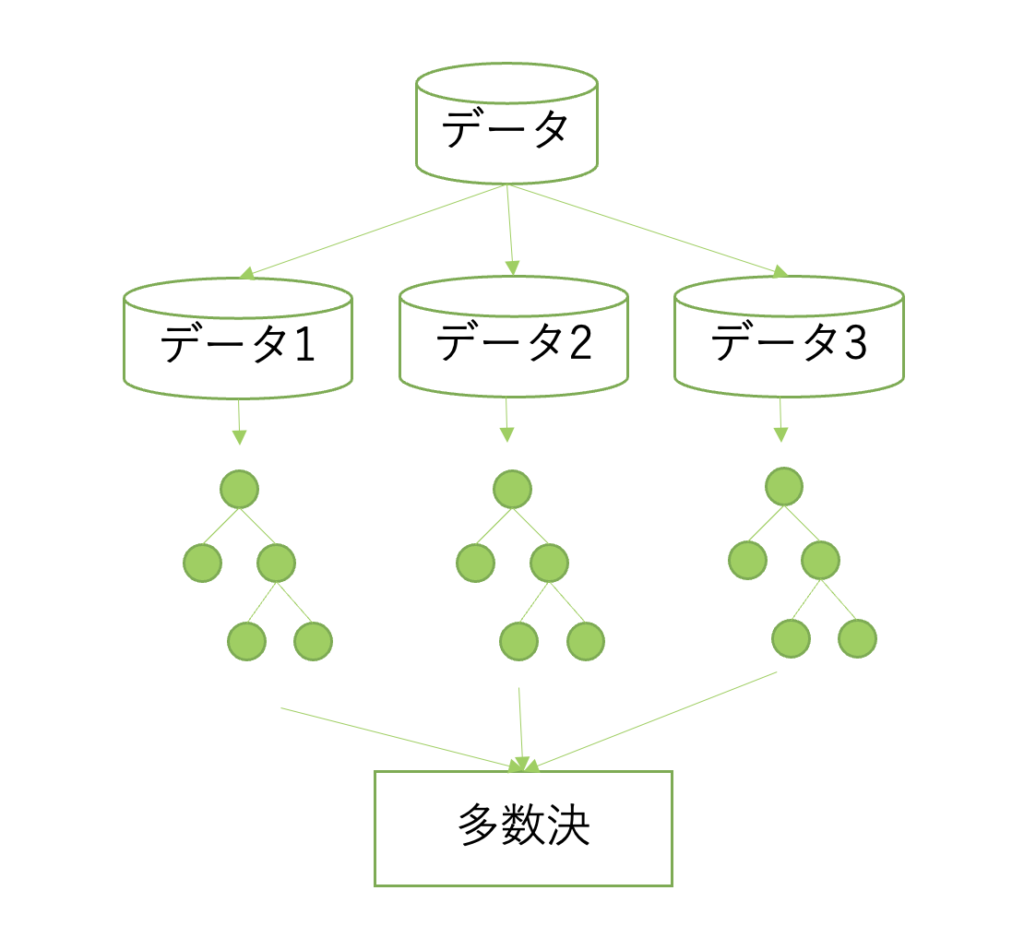
ランダムフォレストは、複数の決定木を独立に作成し、それらの結果を多数決や平均化することで、高い精度での予測が可能な機械学習アルゴリズムです。
これにより、ランダムフォレストは、高次元かつ複雑なデータに対しても堅牢性が高く、過学習を回避しつつ高い汎化性能を発揮することができます。
ランダムフォレストの概要図
Pythonでランダムフォレストを使ってみる
では早速、Pythonでランダムフォレストを使ってみましょう。
ライブラリのインポート
Pythonでランダムフォレスト使うには、scikit-learnライブラリが必要です。
scikit-learnのインストールがまだの方は以下の記事を参考にインストールしておきましょう。
Pythonでランダムフォレストを実行するには、scikit-learnのensembleモジュールからRandomForestClassifierクラスをインポートする必要があります。以下のように、必要なライブラリをインポートします。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreデータの読み込み
ランダムフォレストを使う前に、データを読み込みます。今回は、Irisデータセットを使用します。
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.targetデータの前処理
ランダムフォレストを実行する前に、データを分割する必要があります。
ここでは、データをトレーニングセットとテストセットに分割します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf = RandomForestClassifier(n_estimators=10)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)モデルの構築
次に、ランダムフォレストのモデルを構築します。
ここでは、ツリーの数を10とし、その他のパラメータはデフォルトの値を使用します。
n_estimators=10とすることで、決定木を10個作成し、その結果を統合することで予測を行います。
rf = RandomForestClassifier(n_estimators=10)
rf.fit(X_train, y_train)モデルの評価
モデルを構築したら、その性能を評価する必要があります。ここでは、テストセットを使用してモデルの精度を計算します。
y_pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
#Accuracy: 1.0まとめ
今回の記事では、以下の内容について紹介しました。
- ランダムフォレストについて
→複数の決定木を独立に作成することで、高い精度での予測が可能な機械学習アルゴリズム - Pythonでランダムフォレストを使ってみた
→簡単に高性能な分類ができた!
ランダムフォレストは、決定木のアンサンブル学習モデルであり、非常に高い精度で予測を行うことができます。
非常に使い方も簡単で、高性能な機械学習モデルを作成することができるので、ぜひ皆さんも試してみてはどうでしょうか?

