
こんにちは!
皆さんは、サポートベクターマシン(SVM)という機械学習アルゴリズムをご存知ですか?
サポートベクターマシンは、古典的な機械学習手法であるにもかかわらず、非常に使い勝手が良く、性能も高いと言われているアルゴリズムです。
そのため、とりあえず機械学習みたいなことをやってみたい!という方には、非常におすすめのアルゴリズムです。
サポートベクターマシンは英語で、Support Vector Machineと呼ばれ、SVMと略されることが多いので、以降はSVMと記述します。
今回の記事では、以下の内容について紹介します。
- SVMについて
- PythonでSVMを使ってみた
サポートベクターマシン(SVM)とは
SVMは、教師あり学習の1つで、応用範囲が広く使い勝手が良いので、広く愛用されてきた機械学習アルゴリズムです。
教師あり学習というのは以下の記事で説明しています。
・【機械学習】教師あり学習、教師なし学習について簡単に解説!それぞれのアルゴリズムを紹介
SVMを使うことで、境界線を引くことができ、その境界線によってクラスを分類することができます。
では、どのような条件で境界線を引くのでしょうか?
それを簡単に説明していきましょう。
SVMの動作
SVMでは、サポートベクトル、マージンという言葉が重要になってきます。
サポートベクトルというのは、境界線に一番近いデータ
マージンというのは、サポートベクトルと境界の距離です。
SVMは、このマージンを最大化するように計算することで最適な境界を求めるアルゴリズムです。
以下の図の実線ように境界線が引かれていたとすると、点線と被っている点がサポートベクトル、点線と実線の間の距離がマージンです。
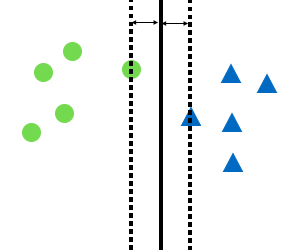
このマージンを最大化するように、境界線を移動させます。
すると、以下の図のようになり、これがSVMによる境界線になります。
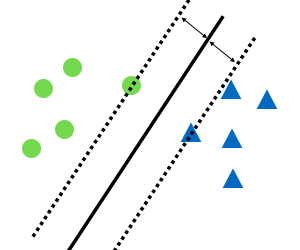
数学的な知識がなくても、この動作さえ覚えておけば、SVMについてはまず大丈夫です。
PythonでSVMを使ってみる
PythonでSVMを使ってみましょう。
今回はirisデータセットを用いて、線形のSVMで学習して分類を行なってみます。
scikit-learn、pandasというライブラリを使用するため、インストールしておきましょう。
ソースコード
from sklearn.datasets import load_iris
from sklearn import model_selection, svm, metrics
import pandas as pd
iris = load_iris()
iris_data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_label = pd.Series(data=iris.target)
data_train, data_test, label_train, label_test = model_selection.train_test_split(iris_data, iris_label, random_state=42)
clf = svm.SVC(kernel="linear")
clf.fit(data_train, label_train)
test_predict = clf.predict(data_test)
ac_score = metrics.accuracy_score(label_test, test_predict)
print(ac_score)解説
iris_data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_label = pd.Series(data=iris.target)
機械学習では、DataFrameを使うとわかりやすく簡単です。
デフォルトでは、トレーニングデータ:テストデータ=7.5:2.5で分割します。
random_stateを設定することで、実行ごとにデータ分割が変わらないようにしています。
clf.fit(data_train, label_train)
linearというのが線形のSVMを使用するということです。
学習にはトレーニングデータを渡してあげましょう。
予測にはテストデータを使います。
実行結果
1.0AUCが1.0ということは、テストデータの予測が完璧に行えているということです。
まとめ
今回の記事では、以下の内容について紹介しました。
- SVMについて
→古典的だが強力な機械学習アルゴリズム
マージンを最大化させるように境界線を引く - PythonでSVMを使ってみた
→簡単に高性能な分類ができた!
皆さんも是非試してみてください!

