
こんにちは!
皆さんは、決定木という機械学習アルゴリズムをご存知ですか?
決定木は、機械学習の中でも代表的なアルゴリズムの一つです。
決定木は、データ分析や予測モデル構築に広く使われており、理解しておくと機械学習において大変役立ちます。
今回の記事では、Pythonを用いた決定木の基礎的な使い方について、以下の内容をご紹介しbvます。
- 決定木について
- Pythonでの決定木の使い方
決定木とは
決定木は、データ分析や予測モデル構築に広く使われる機械学習アルゴリズムの一つです。
それでは、決定木の概要を見ていきましょう。
決定木の概要
決定木は、データの特徴量を使って木構造の分類モデルを構築する手法で、ツリー構造の中でデータを分割し、それぞれの分割領域において別々の予測を行います。また、決定木は、分類だけでなく回帰にも応用できます。
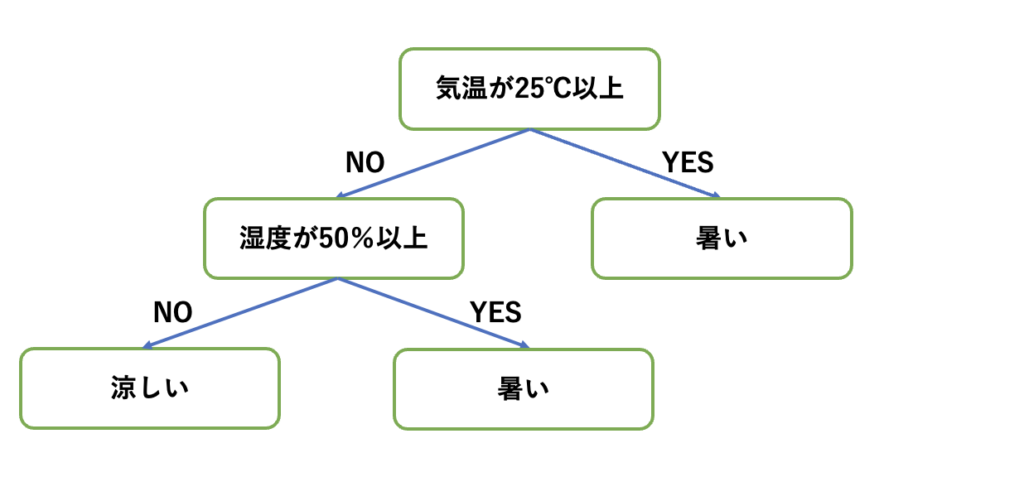
決定木の特徴
決定木の特徴として、以下のようなものがあります。
・分類に優れる: 決定木は、分類問題において高い精度を発揮します。
・データの前処理が簡単: 決定木は、欠損値や異常値を含むデータに対しても比較的に強いです。
・モデルの解釈がしやすい: 決定木は、ツリー構造で表現されるため、可視化することができ、モデルの解釈がしやすいです。
Pythonで決定木を使ってみる
では早速、Pythonで決定木を使ってみましょう。
Pythonでの決定木の実装方法
Pythonでの決定木の実装には、scikit-learnという機械学習ライブラリを使うのが一般的です。scikit-learnには、決定木の実装や可視化などに必要な機能が提供されています。具体的には、DecisionTreeClassifierやDecisionTreeRegressorといったクラスを使用することで、分類や回帰の決定木を構築することができます。
以下は、scikit-learnを使った決定木の実装例のコードです。
ここでは、Irisデータセットを使って、花の種類を分類する決定木を構築する方法を示します。
ソースコード
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# データの読み込み
iris = load_iris()
X = iris.data
y = iris.target
# 学習用データとテスト用データに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 決定木の構築
clf = DecisionTreeClassifier(random_state=0)
clf.fit(X_train, y_train)
# テストデータでの評価
score = clf.score(X_test, y_test)
print(f"Accuracy: {score:.2f}")
#Accuracy: 0.97まとめ
今回の記事では、以下の内容についてご紹介しました。
- 決定木について
→データの特徴量を使って木構造の分類モデルを構築する手法 - Pythonでの決定木の使い方
→簡単に高性能な分類ができた!
決定木は、非常に有名なランダムフォレストという機械学習アルゴリズムの元となるアルゴリズムでもあるので、しっかりと使えるようになっておきましょう!
ランダムフォレストの使い方を知らない方は、以下の記事を参考にしてください。
