
こんにちは!
皆さんは、Pythonで特徴量やカテゴリごとに分布を可視化したいなと思ったことはありませんか?
特徴量やカテゴリごとの分布の可視化は、Seabornの「stripplot()」「swarmplot()」を使うと簡単に可視化することができますよ。
Seabornライブラリのインストールが終わっていない方は、インストールしておきましょう。
今回の記事では、以下の内容について紹介します。
- stripplot()の使い方
- swarmplot()の使い方
特徴量やカテゴリごとの分布を可視化する「stripplot()」「swarmplot()」
特徴量やカテゴリごとの分布を可視化するには、「stripplot()」「swarmplot()」を使います。

stripplot()
stripplot()の基本的な書式は以下になります。
特徴量ごとの分布を可視化したければ、x, yは指定する必要はありません。
xに指定したカテゴリデータ列内のカテゴリごとに、yで指定した特徴量の可視化を行います。
特徴量ごとの可視化
以下のプログラムは、irisデータセットの特徴量ごとの分布を可視化するプログラムです。
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target_names[iris.target]
sns.stripplot(data=df)
plt.show()実行結果
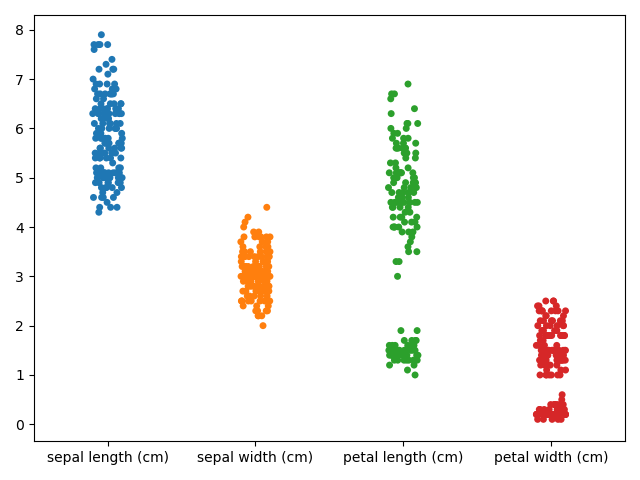
今回使用したデータは「species」というカテゴリデータ(文字のデータ)の列がありますが、x, yを指定しなかった場合には、そういったカテゴリデータを含んでいる列は除いて出力してくれるみたいですね。
カテゴリごとの可視化
以下のプログラムは、irisデータセットの「species」内のカテゴリごとの「sepal length (cm)」の分布を可視化するプログラムです。
sns.stripplot(x='species', y='sepal length (cm)', data=df, hue='species')実行結果
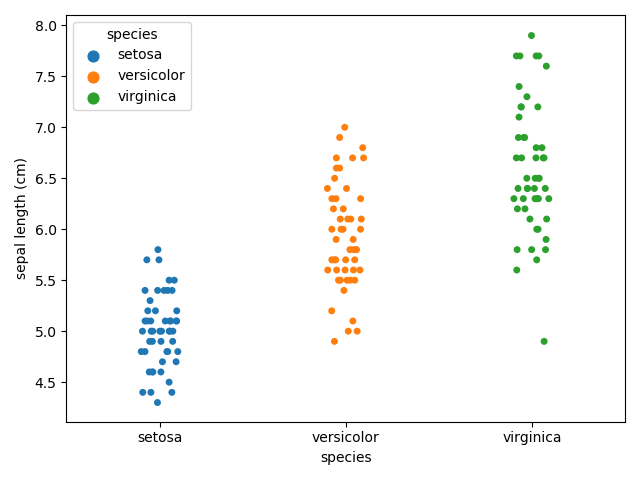
swarmplot()
stripplot()を使用する場合にはデータが重なって出力されていましたが、swarmplot()では、データの分布が重ならないように出力してくれます。
stripplot()の基本的な書式は以下になります。
特徴量ごとの可視化
以下のプログラムは、irisデータセットの特徴量ごとの分布をデータの重なりが無いように可視化するプログラムです。
sns.swarmplot(data=df)実行結果
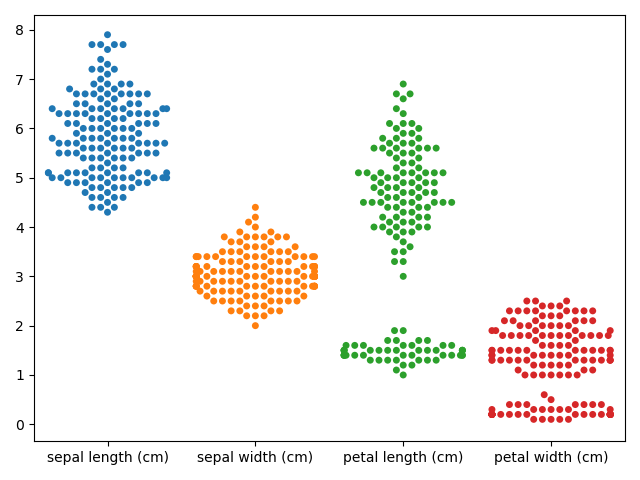
カテゴリごとの可視化
以下のプログラムは、irisデータセットの「species」内のカテゴリごとの「sepal length (cm)」の分布をデータの重なりが無いように可視化するプログラムです。
sns.swarmplot(x='species', y='sepal length (cm)', data=df, hue='species')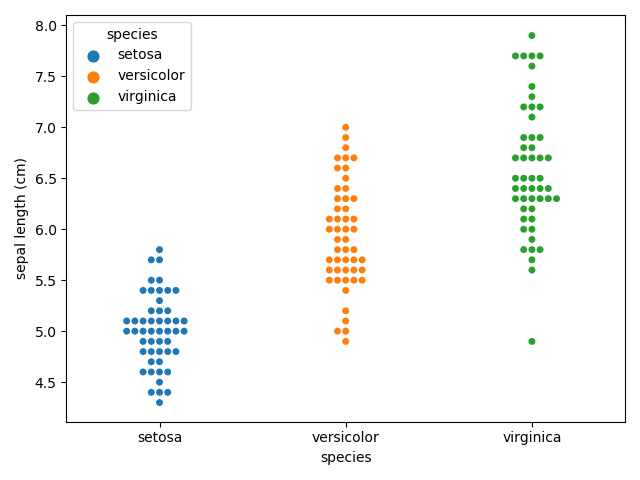
まとめ
今回の記事では、以下の内容について紹介しました。
- stripplot()の使い方
→表示したいデータを指定 - swarmplot()の使い方
→データの重なりが無いように可視化
特徴量やカテゴリごとに分布を可視化できるようになって、データの特徴をつかむのに役立てましょう!

