
こんにちは!
皆さんは、Pythonで散布図行列表示したいと思ったことはありませんか?
散布図行列を使うと、一度に複数の対の散布図を確認することができ、データの特徴をつかむのに役立ちます。
Pythonで散布図行列を作成するには、Seabornライブラリの「pairplot()」を使えば簡単に表示することができます。
Seabornライブラリのインストールが終わっていない方は、インストールしておきましょう。
今回の記事では、以下の内容について紹介します。
- pairplot()の基本的な使い方
- pairplot()の様々なオプション
散布図行列を表示する pairplot()
散布図行列を表示するには「pairplot()」を使います。

pairplot()の基本的な使い方
pairplot()の基本的な書式は以下になります。
以下のプログラムは、irisデータセットの散布図行列を表示するプログラムです。
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target_names[iris.target]
sns.pairplot(df)
plt.tight_layout()
plt.show()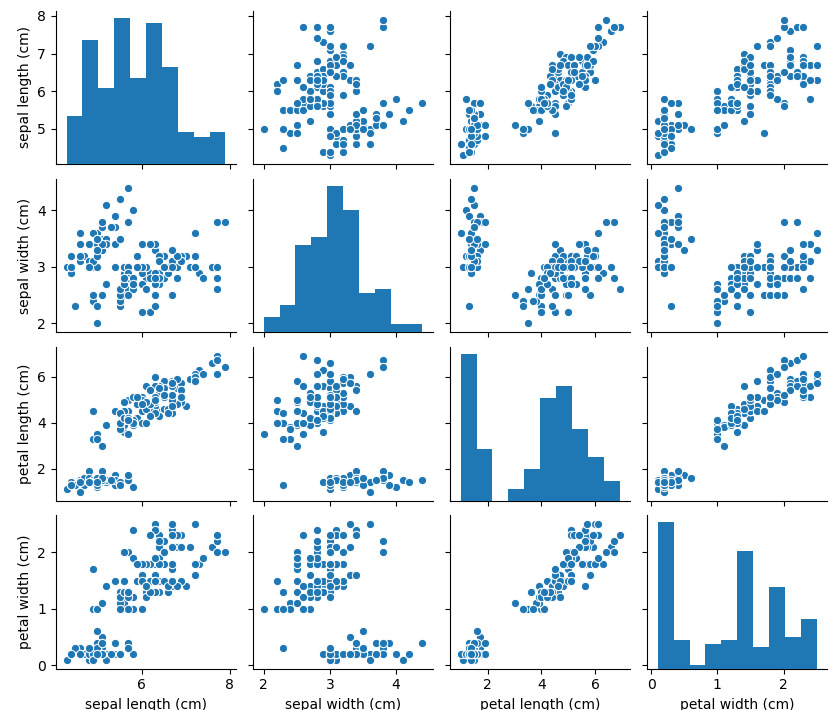
様々なオプション
よく使われるオプションを紹介します。
すべてのオプションが気になる方は、公式ドキュメントを参照してください。
| オプション | 説明 | デフォルト値 |
| hue | カテゴリデータごとに色分け | |
| vars, x_vars, y_vars | 出力する行、列を指定 | |
| diag_kind | 対角上のプロットの種類の選択 | auto |
| height | グラフのサイズを指定 |
hue
「hue」にカテゴリデータが格納された列名を指定することで、カテゴリ名ごとに色分けすることができます。
sns.pairplot(df, hue='species')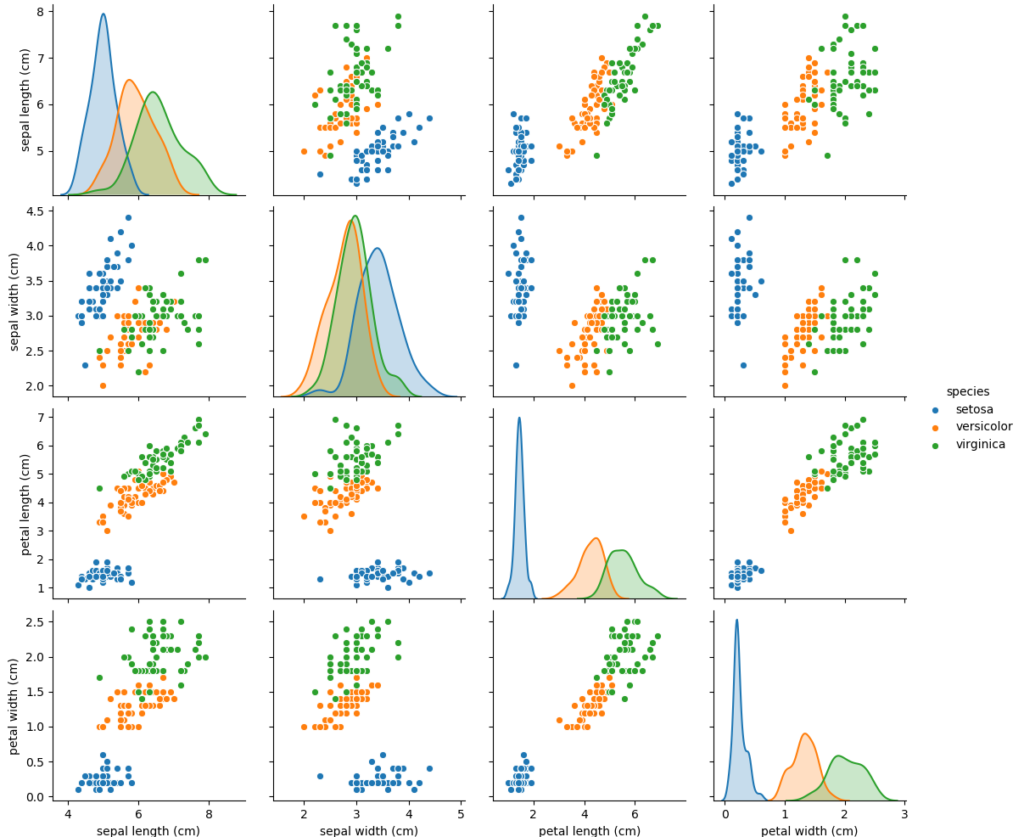
vars, x_vars, y_vars
「vars, x_vars, y_vars」を指定することで、グラフに出力する行、列を指定できます。
行と列両方同じカテゴリ名を指定する場合にはvars、
行と列で違いカテゴリ名を指定する場合にはx_vars、y_varsを使用します。
sns.pairplot(df, vars=['sepal length (cm)', 'petal length (cm)'])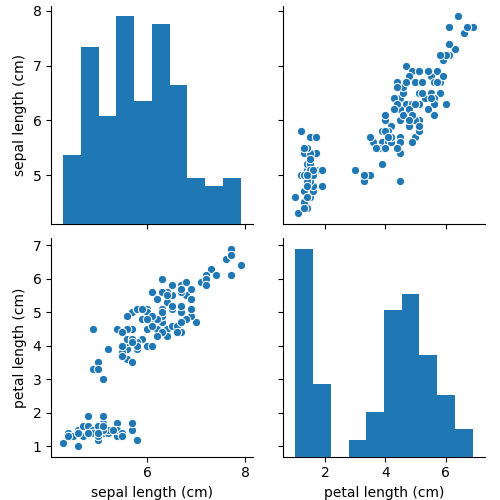
sns.pairplot(df, x_vars=['sepal length (cm)', 'petal length (cm)'], y_vars=['sepal width (cm)', 'petal width (cm)'])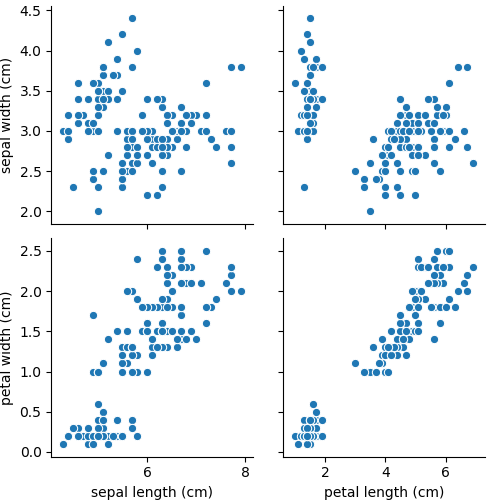
diag_kind
「diag_kind」に指定する値を変更すると、対角上のプロットの種類を変更することができます。
histでヒストグラムを、
kdeでカーネル密度推定のグラフを出力します
デフォルト値はautoでautoの場合は、hueを指定しているかどうかでヒストグラムとカーネル密度推定のどちらを出力するかが変化します。
hueを指定していない場合には、ヒストグラムを、
hueを指定している場合には、カーネル密度推定を出力します。
sns.pairplot(df, diag_kind= 'kde')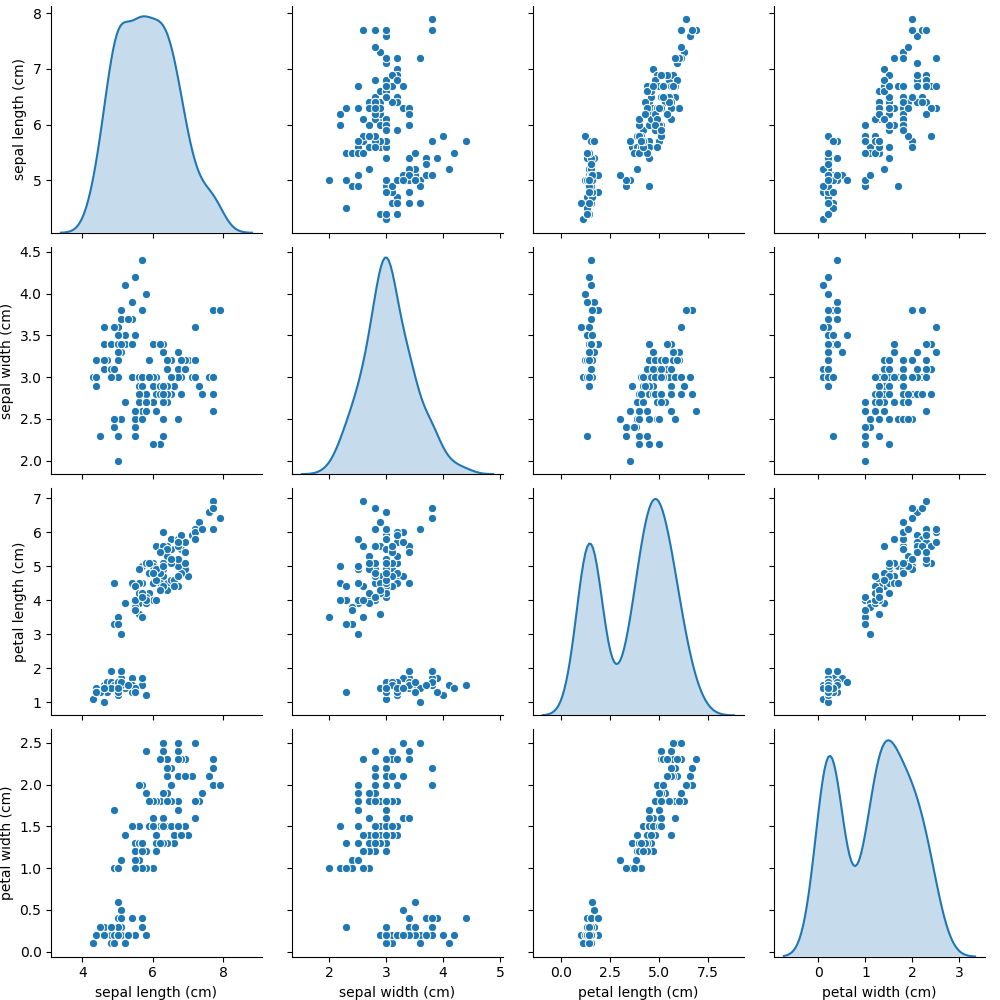
height
「height」で出力するグラフのサイズを指定します。単位はインチです。
sns.pairplot(df, height=1.5)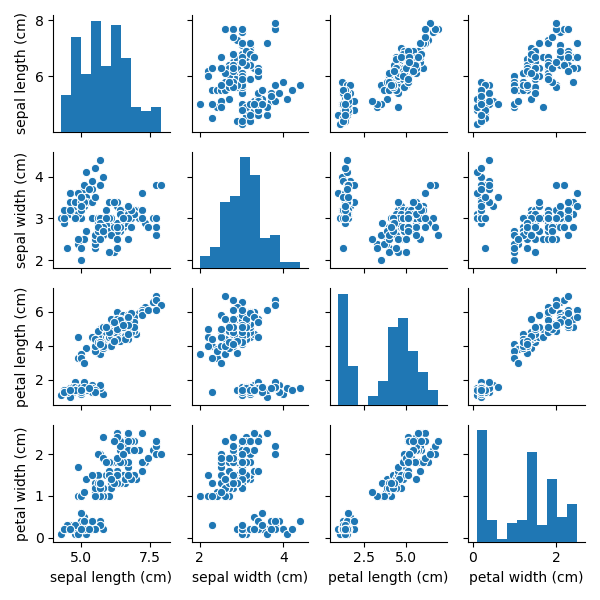
まとめ
今回の記事では、以下の内容を紹介しました。
- pairplot()の基本的な使い方
→データを指定
すべてのカテゴリデータを使った散布図行列を出力 - pairplot()の様々なオプション
→色分けが簡単にできるetc…
散布図行列を出力する方法をしっかりと覚えて、データの特徴をつかむのに役立てましょう!

