
こんにちは!
皆さんはpdfファイルからテキストを抽出したいと思ったことはありませんか?
今回の記事では、以下のpdfファイルの抽出方法を紹介します。
- pdfminer.sixを使ったpdfファイルの抽出方法
投資、就活、英語についての記事を書いています。
気になる方は是非見てみてください!
pdfminer.sixモジュール
pdfminer.sixモジュールとは
「pdfminer.six」モジュールとは、pdfからテキストを抽出するために作成されたPythonのモジュールです。
pdfminer.sixは日本語に対応しているため、日本語のテキストも抽出することができます。

pdfminer.sixモジュールのインストール方法
pdfminer.sixモジュールをインストールするには、以下のコマンドを入力しましょう。
pip install pdfminer.sixこのモジュールをインストールすると、同時にとあるプログラムもダウンロードされます。
超簡単にpdfファイルからテキストを抽出しよう!
テキストを抽出するプログラムを用意する
今回の記事で、pdfファイルからテキストを抽出する際に何が超簡単なのか、それは先ほど述べた同時にダウンロードされるプログラムに秘密があります。
そのプログラムの名前は、「pdf2txt.py」という名前です。
このプログラムは、pdfファイルからテキストを抽出するために作成されたプログラムです。
そのため、pdfファイルからテキストを抽出するには、プログラムを実行するだけです。
だから超簡単なんですね。
インストールされている場所がわからない方は、素直にファイル検索をしましょう。
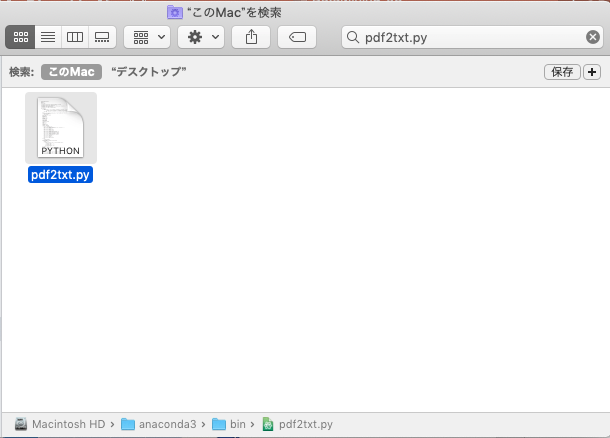
ちなみに、macでanacondaを使用している自分の場合は、
Macintosh HD/anaconda3/bin/pdf2txt.py
というディレクトリ構造になっています。
pdf2txt.pyと、テキストを抽出したいpdfファイルを移動させて、同じディレクトリ内に入れておきましょう。
これで準備は完了です。
pdf2txt.pyを実行
早速pdf2txt.pyを実行していきましょう。
実行する際は、「テキストを抽出したいpdfファイル」を引数として指定します。
今回はsample.pdfという以下のpdfファイルからテキストを抽出していきます。

実行を試してみたいけどpdfファイルが無い!という方は下のダウンロードからsample.pdfをダウンロード可能なので是非ダウンロードしてみてください!
python3 pdf2txt.py sample.pdf実行結果
この pdf ファイルはサンプルです。
この pdf ファイルはサンプルです。
この pdf ファイルはサンプルです。
この pdf ファイルはサンプルです。
どうでしょうか?sample.pdfでは、文字の大きさがそれぞれ行ごとに違いますが、pdf2txt.pyを実行すると、文字の大きさに関係なくテキストを抽出できていますね!
注意事項
今回の簡単なpdfファイルではうまくテキストを抽出することができました。
しかし、pdfには様々なバージョンがあったり、暗号化が行われテキストを抽出できないようにしているものもあります。
さらには、文章が多段構成だった場合には、うまくテキストを抽出できないといった問題もあります。
以下の点を念頭に置いて実行するようにしましょう。
このような問題を解決するためには、pdfファイルごとにテキストを抽出するプログラムを書き換えるしかありません。
そのため様々な形のpdfファイルを扱うにはあまり向いていません。
同じような形式のpdfファイルをたくさん扱い、テキストを抽出する場合には非常に有効ですので、ぜひやり方を覚えておきましょう!
まとめ
今回の記事では、以下のpdfファイルの抽出方法を紹介しました
- pdfminer.sixを使ったpdfファイルの抽出方法
→pdf2txt.pyを実行するだけ
全てのpdfファイルをうまく抽出できるわけではない
注意事項をしっかりと頭に入れて、様々なpdfファイルからテキストを抽出してみましょう!

